
“范式变化这个词在AI圈子被用的有点叙事过载了。”
在底本盘算推算的春节首发期间点昔时两个多月后,DeepSeek V4终于庄重发布。关于这一代模子,外界有着极高的和蔼度,但也伴跟着诸多疑问:为何资格了如斯永远间的推迟?在现实应用中发扬何如?

近日,两位一线AI研发与算力框架从业者(刘易峰与赵晨阳)在播客中对V4的技能论述进行了详备的推敲。他们方位的团队致使在V4发布今日,就完成了推理和强化学习两条链路的跑通。本文将基于他们的实测反馈与技能剖判,为您复兴一个确凿的DeepSeek V4。

智商稳居第一梯队,但堕入“Token耗尽”逆境
在模子发布后,测试其确凿智商的直不雅神志即是进行“盲测”。现在在Arena竞技场等主流盲测平台上,V4梗概排在第23位摆布,其抽象评分与千问3.5 Max、GLM 5.1、Kimi K2.6等国内第一梯队模子处于吞并区间。
从现实使用体感来看,在数学推理、代码编写以及撤职Agent(智能体)领导扩充方面,V4比上一代的V3有权臣栽种,且幻觉发生率大幅度减少。不外,在最中枢的代码智商上,与现在国际顶尖的闭源模子(如Claude、GPT的最新版块)比较,仍存在一定差距。
但在各项智商栽种的背后,从业者们不雅察到了一个广宽存在且亟待贬责的问题——算力资源的任性奢靡。

在使用V4及同类最新模子贬责吞并个问题时,模子耗尽的Token(词元)数目比以前大了许多。从业者将其形容为“拿着高压水枪浇花”。这并非模子自身的残障,而是模子诚实反应了其受到的强化学习老师方针:模子倾向于用更长的推理门径来确保拿到正确的最终奖励。诚然V4通过底层优化极地面裁减了单Token的生成本钱(其Flops仅占V3.2的27%,KV缓存仅占10%),但贬责单一问题总时长的加多,标明总共行业需要从头想考:在追求极长高低文的同期,何如提高模子诳骗高低文的现实成果。

四项底层技能的“组合爆炸”
V4之是以比预期晚了两个多月发布,很猛经由上是因为它并非在原有框架上作念简便的修补,而是一次性引入了四个彼此高度耦合的底层新特质。在极其宏大的模子畛域上,单独上线任何一个新功能皆需要极大畛域的排错考证,四个技能重复,告成导致了工程上的“组合爆炸”。
1. 搁置MLA,重构搀和重见地机制 在V3期间,DeepSeek提倡了MLA架构,并被后续诸多开源模子(如Kimi K2系列、GLM 5系列)普通采用。但在V4中,研发团队烧毁了这一技能,转而采用了搀和滑动窗口(SWA)与长程重见地的机制。具体而言,模子在不同的网罗层中,会事先界说使用CSA(在序列维度作念4:1压缩)如故SCA(作念128:1的极点压缩保抓繁密)。稀少层负责锁定要害信息,繁密层提供语义概览。这种重构大约大幅栽种百万字长文本的处理成果,但给底层的缓存一致性(尤其是前缀缓存机制)带来了极大的拓荒难度。
2. 引入MHC(多头邻接)拓展信息流 传统的Transformer架构中,信息频繁是逐层传递的。V4采用了MHC技能,特殊于在层与层之间告成建立更宽的信息通说念。这种作念法能权臣提高逻辑推聪敏商,使得信息不需要恭候一层层徐徐传递。关系词,这种跨层邻接在数学旨趣上容易导致梯度回传极不踏实(发生爆炸或消灭)。V4通过特定的算法将信息流的畛域严格适度为1,才得以将其得胜应用到工业级大模子中。

3. 全面转向Muon优化器 模子老师优化的主流器用曾永远是AdamW,它针对单个元素进行更新。而V4全面采用了基于矩阵合座更新的Muon优化器。通过将总共矩阵视为一个合座,各元素之间的设施更为一致,从而加速管理速率。V4致使在此基础上找到了一个更为精确的全局学习率参数(0.18)。但这也意味着,抢庄牛牛app下载在差别式老师时,工程师必须对宏大的矩阵进行更为复杂的切分和通讯鼎新,极其熟习底层的工程终了智商。
4. 攻克FP4极限精度的工程落地 将浮点数的数据存储位宽从FP8进一步压缩至FP4,是斩断显存容量和数据读取带宽瓶颈的要害技能。但由于FP4的数值畛域极其短促,老师中极易出现梯度溢出。为了贬责这一贫乏,研发团队使用了“量化感知老师”:在老师阶段将FP32的主权重模拟压缩到FP4畛域,再无损反量化回FP8进行商量(使模子稳当低精度亏蚀);而在确凿的强化学习采样阶段,则使用确凿的FP4权重(终了W4A4级别的物理提速)。

消灭的老师本钱与极限的激活参数
在V3发布时,官方曾明确清楚其临了一次老师本钱为557万好意思元。但在V4的技能论述中,这一数据消灭了。
从业者分析合计,不再主动公开本钱,标记着研发团队不再需要依靠单一的“廉价”标签来界说自身。最终模子临了一次的老师跑通,只是是一起本钱的冰山一角。在此之前,广宽的前沿技能探索、对比实验、东说念主力以及数据筛选所耗尽的资金,时常是最终一次老师本钱的几十倍。
与此同期,论述中清楚了另一个值得行业和蔼的数据:V4 Pro的总参数达到了1.6万亿(1.6T),但其在处理任务时的激活参数仅为500亿摆布,激活比例刚刚逾越3%。
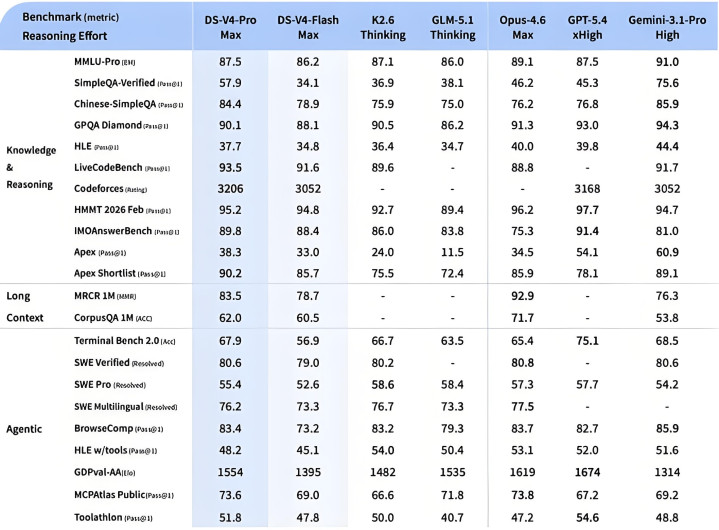
现在行业内同期的顶尖模子,如千问3.5 Max激活比例为4.3%,GLM 5.1为5.3%,Kimi K2.6为3.2%。V4进一步向下试探了激活比例的极限。MOE(搀和大师模子)的中枢价值即是将“总学问量”与“单次推理本钱”解绑,V4将这种解绑推向了极致。在领有1.6万亿参数储备的同期,仅用小数的算力进行精确回答。在如斯宏大的参数基数下,大约保证广宽大师模块老师的负载平衡和路由分派不出错,评释了团队在工程机制上的深厚蓄积。

评测危境与基础生态诞生
在算力生态方面,V4的技能论述中明确提到,其在推理层面原生扶植了华为昇腾等国产芯片,并完成了技能考证。在底层算子编写上,它也广宽采用了国内发展起来的开源编译话语(如Triton和Talon),这极地面裁减了新算法拓荒高性能内核的角落本钱。
面对近期密集发布的各大模子,业内也面对着一种“评测危境”(Evaluation Crisis)。现存的基准测试(Benchmark)一朝发布,时常在半年到一年内就会被各家模子“刷满”至90分以上。关系词,在现实搪塞复杂的长程对话或代码合并等确凿场景时,用户照旧能感受到彰着的相反。无法准确评估,就无法训诲正确的优化主义。何如建立针对智能体(Agent)和多步复杂任务的更可靠评测体系,将是全行业下一步的重点。

纵不雅V4的发布,它并莫得在“原生多模态”等主张上过度着墨,而是极其求实地聘请了深挖文本处理与底层商量成果。正如斯次发布时官方援用的《荀子》名言:“率说念而行,端然正己……不囿于誉,不恐于谤。” 吩咐蔓延发布的表里压力,将长高低文、极低激活比例、极低单Token本钱的工程配方绝对跑通并考证,DeepSeek V4竖立了开源大模子寰球的一项全新工业标准。

结语
跟着各大模子高低文长度的不停冲破抢庄牛牛,您在日常使用AI时,是否也遭受过模子为了完成任务而“过度啰嗦”的情况?关于翌日大模子的发展,您更敬重其“反应速率与本钱”,如故更期待其具备确凿颓唐完成复杂责任的“智能体”智商?接待在辩驳区共享您的确凿体验。
开云app在线下载入口上一篇:抢庄牛牛app下载 中国重汽2026年一季度营收净利双增 迎来功绩开门红
下一篇:没有了
 备案号:
备案号: